Character Generation with Recurrent Neural Networks
Overview
Post is for this repo. This informal project was inspired by Andrej Karpathy’s RNN blog from 2015 here (Karpathy, Andrej, 2015) and associated code here. Brazenly uses a lot of the structures and code from the Keras tutorial here.
RNNs for Character Generation
One of the confusing (to me) aspects of Recurrent Neural Networks (RNNs) is the way the network is typically depicted in diagrams. It’s not until you see that the stages from left to right are actually the same network but at different times that it all slots into place.
The successive stages of the RNN from left to right as actually the same RNN structure but just represented in new states across time. So the leftmost stage is at t=0, the second leftmost stage at t=1, and so on.
The special characteristic in RNNs of feeding back the prior hidden state is simply then the arrow showing the hidden state passed from the prior time stage to the current. The labeling of the input characters then makes intuitive sense, with the leftmost as the first character, the second leftmost as the second character and so on.
Then the references to RNNs representing networks that are very deep with shared weights make sense–the very deep characteristic comes from the repeated execution of the same network and the shared weights are the weights retained each cycle of the RNN.
The diagram below (courtesy of (Karpathy, Andrej, 2015)) shows variations on how RNNs can produce outputs from different inputs, with that depiction of successive stages in time.
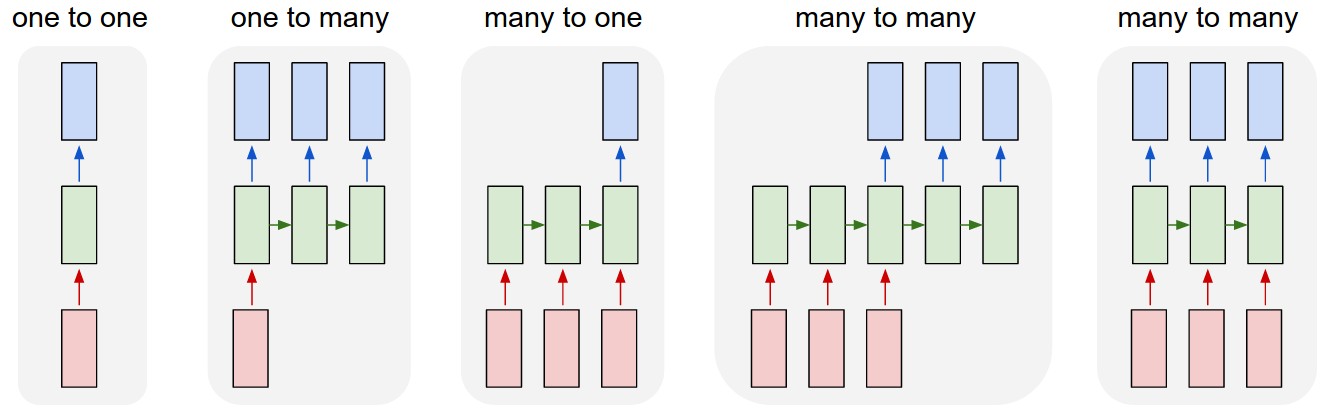
Figure 1: RNN input/output variations
Statistical Prediction of the Next Character
With all the hype and furore around AI currently it is helpful to go back to some of the fundamentals and see basic generative networks operating. It reminds you that the algorithmic principle here is one of statiscal likelihood based on frequencies of certain characters following other characters included in a training set. In the case here a subset of Shakespeare’s works.
Seeing the improved quality of the output as you add layers, increase the complexity of the network with GRU and LSTM structures, helps you avoid anthropomorphizing the system that produces the output. A valuable exercise. A good article on the risks of this tendency is here (Shanahan, Murray, 2023).
Take for example the characters generated from the untrained network:
seZSQJLFkmDfgITR?omHkv[UNK]ERUTwP!oGaAauVk[UNK]?pwIB!nS$Mtxs: hLP$qgSIVrcGuYD?borXGBE\nnQfwmbbth$yIwWgPOzA,Iw
And then sample characters from a trained network:
GRUMIO:
A deepless lamb; thou hast offended him
An answerning of it it is past, and vasted thou our princess,
The early passage of a law at unnis,
Nothing else changed, the calculations performed in producing characters in each case were the same, it was just that with the latter the weights were not just random initializations but tweaked by passing the training data through and adjusting to improve prediction accuracy.
Code and Approach
Source data is obtained from:
path_to_file = tf.keras.utils.get_file('shakespeare.txt', 'https://storage.googleapis.com/download.tensorflow.org/data/shakespeare.txt')
Initial code in the ipynb Jupyter files includes generating the character embeddings so that the input data is suitable for the network to use. General setup parameters user for the models themselves were:
BATCH_SIZE = 64
embedding_dim = 256
rnn_units = 1024
The codebase includes three model definitions, using SimpleRNN, GRU and LSTM layers. The RNN version has just one layer, the others two. Choices here were a bit arbitrary.
RNN Model
Single layer SimpleRNN defined as a MyModel class:
class MyModel(tf.keras.Model):
def __init__(self, vocab_size, embedding_dim, rnn_units):
super().__init__(self)
self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)
self.rnn = tf.keras.layers.SimpleRNN(rnn_units,
return_sequences=True,
return_state=True)
self.dense = tf.keras.layers.Dense(vocab_size)
For a total 1.3 million trainable parameters:
Model: "my_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) multiple 16896
simple_rnn (SimpleRNN) multiple 1311744
dense (Dense) multiple 67650
=================================================================
Total params: 1,396,290
Trainable params: 1,396,290
Non-trainable params: 0
_________________________________________________________________
Sample generated output from initial phrase:
PEANUT:
Ay, and thy foots the son of standent, as it is not stone to him, but yetress thee.
ProRINAUD:
Even to the realm crapp'd not of brother,
Traitor, thy son before love.
PAULINA:
I thank there was never be no walls,
Like intentest house: sir, alas!
GONZALO:
I was yourselves
To be the dark mastrius with wings I'll give my brother would
her in such an ounseloss as a late mine own king
I'll would out on.
Has the basic structure, sequences of words and some similarity to the language used in the training. But nothing very readable.
GRU Model
GRU model with 2 layers, 10 million trainable parameters, defined also as a class:
Model: "my_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) multiple 16896
gru (GRU) multiple 3938304
gru_1 (GRU) multiple 6297600
dense (Dense) multiple 67650
=================================================================
Total params: 10,320,450
Trainable params: 10,320,450
Non-trainable params: 0
_________________________________________________________________
This model generates some more believable output, better sentences and some continuity line to line:
PEANUT:
Money, and daughters; mine were the very cain
for country's breath; and that thou mayst be ripe me?
RIVERS:
And that's the wayer of the king nor day.
ROMEO:
O, then, dear saint, let lips do what hand I saw it,
Invied them as my sovereign; lesser's head
Go weight it out.
Masters are most desire.
DUKE OF YORK:
My lords of England, let your general good.
ANGELO:
This is a good trafely in this hour here to beg
Than the imagination of my womb.
ANGELO:
Stay a little in this presence,
It busial black fatal hands,
Some quafits before my wars on you: look to't:
We enjoy the loving hosour means.
LSTM Model
2 layer LSTM model, 14 million parameters:
Model: "my_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
embedding (Embedding) multiple 16896
lstm (LSTM) multiple 5246976
lstm_1 (LSTM) multiple 8392704
dense (Dense) multiple 67650
=================================================================
Total params: 13,724,226
Trainable params: 13,724,226
Non-trainable params: 0
_________________________________________________________________
Tough to see a clear contrast with the GRU output, pretty good considering the simplicity of the model structure:
PEANUT:
Alas! how light for wrong for a cause!
MOPSA:
He's bell.
GRUMIO:
A deepless lamb; thou hast offended him
An answerning of it it is past, and vasted thou our princess,
The early passage of a law at unnis,
We have it seen and broud and frightful whiles
That was a tining-roofly, whereing Bolingbroke
Did us her party: and here still I be?
I'll make him not for this directled;
And leave your mind than his offences by woe.
But Here's watch this body in recriot?
RICHARD:
I come, in any ingratition of my woes!
Farewell, my lord. Most obe it ears.
RICHMOND:
All comfort that the dark night to him obe.
There is the bil till Warwick and the English crown.
Summary
It’s a helpful exercise to go through the motions of training a simple RNN for character generation. It serves as an effective reminder of what neural networks of this configuration actually do: predict the most likely next word or character in a sequence.
Loss comparison across the three models shows the improved performance over 30 epochs of the GRU and LSTM models compared to the single layer RNN. The loss graph interesting does show some degradation in performance right at the 30th epoch, which would be worth investigating further.
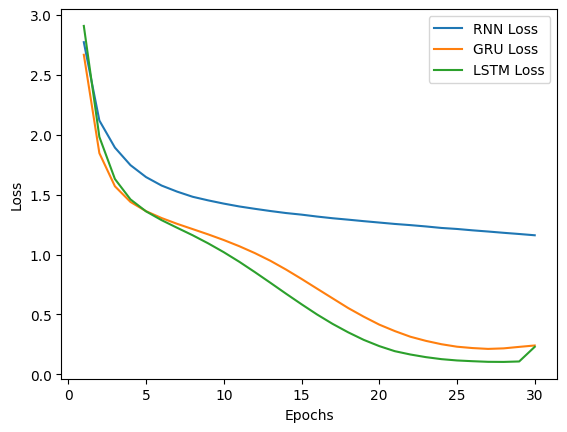
Figure 2: Loss comparison across models
Performance could be improved with addition of further layers. But with these simple, low-complexity models the outputs generated are already entertaining and impressive. Taking all of 10-30mins to train (and way quicker if you have higher performance hardware) these are fun and interesting examples to explore.
References
Karpathy, Andrej (2015). The {{Unreasonable Effectiveness}} of {{Recurrent Neural Networks}}.
Shanahan, Murray (2023). Talking about Large Language Models.